Synchronizing the same set of data across multiple servers is a common practice that is followed to ensure the availability of data across various servers. In MongoDB, replication can be implemented for the processing where it is taken care of that same data is accessible on more than a single MongoDB server. Through this concept of MongoDB, the availability of data increases. In this chapter, you will learn about this concept.
How the Concept of Replication Helps
The concept of replication offers redundancy or duplication of data, which accordingly augments data availability as numerous copies of data will be accessible from different database servers. Replication also helps in protecting a database from the loss of a particular server. Data can be recovered in case there are a hardware failure or service interruptions through this concept and approach. As there are additional copies of the same data on various servers, a single server can prove worthy in case of disaster recovery, reporting, or act as backup.
Advantages, Needs and Disadvantages of Replication
Advantages and Needs of Data Replication:
Here are some of the essential points that you can keep in mind before implementing the concept of data replication in MongoDB:
- Helps in disaster recovery and backup of data.
- 24 by 7 (24 x 7) availability of every data.
- Data can be kept safe through this redundant backup approach.
- Minimizes downtime for maintenance.
Disadvantages of Data Replication:
- More space required.
- Redundant data is stored, so more space and server processing required.
How Replication Works in MongoDB
MongoDB makes use of a replica set to achieve replication. Replica sets are collections of mongod instances which targets to host the identical dataset. There is only one primary node associated with the replica set.
- To perform this, a minimum of three nodes are required.
- In this operation of replication, MongoDB assumes one node of replica set as the primary node and the remaining are secondary nodes.
- From within the primary node, data gets replicated to secondary nodes.
- New primary nodes get elected in case there is automatic maintenance or failover
Here is a block diagram of how the replication in MongoDB takes place:
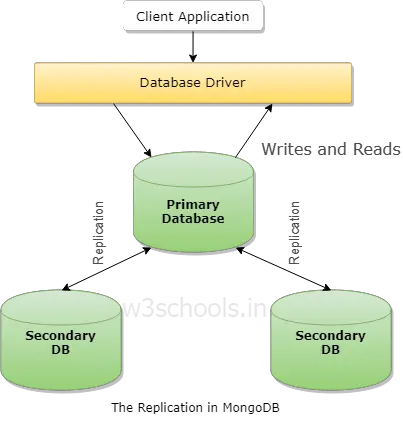
Setup You Replica Set
Now, you will convert a standalone MongoDB instance to a replica set. For this, you have to take the following measures first:
- Stop your currently executing MongoDB server.
- Restart the MongoDB server by indicating 'replSet' option. The necessary syntax is --replSet
Syntax:
mongod --port "PORT" --dbpath "your_db_complete_path" --replSet "instanceName_of_Replica_set"
Example:
mongod --port 27017 --dbpath " C:\Program Files\MongoDB\Server\4.0\data" --replSet rs0
So the above command will:
- Initiate a mongod instance having the name rs0 and is running on port 27017.
- Initiate the command prompt and hook up to your mongod instance.
- Be executing the command rs.initiate() will help start a new replica set.
- Ensure the configuration of a replica set and execute the command rs.conf(). Also, employ the method/command rs.status() for checking the status of the replica set.
Include Members to Replica Set
Start your mongod instances on different machines. Then, initiate your mongo client application and use the method/command rs.add() which is used to include members. The syntax of this method is:
Syntax:
rs.add (hostname : PORT)
Here is an example of how to implement the same:
Example:
rs.add ("mongod1.net : 27017")